PDF is a very popular file format, created by Adobe in 1993. Its purpose is to create documents that will look exactly the same everywhere, even when printed. The only problem is that usually, the information contained in this type of files is not easily modified nor extracted by a machine. As expected the information it contains is arranged in a way it makes it easy to display the document, but makes it almost impossible to be read without a PDF reader.
To have an idea of how a PDF looks in its interior, open a PDF file with any text reader such as notepad in Windows. For those who’d like to have an introduction about the structure of PDF files, please read this carefully written article.
About a year ago I built a software utility to convert huge PDF tables to Excel files in order to work and manipulate their data.
It wasn’t an easy task, it took me some time to read the PDF reference (ISO 32000-1). Once I understood how PDF works internally I searched the net to find open source libraries, that with some hope, would match my needs. I found a lot of interesting projects : lots of pdf readers, pdf creators and text extractors, but no one had done what I was trying to achieve. And the commercial utilities that existed by the time didn’t work as expected. So I created my PDF parser.
Fortunately the tables I wanted to extract where always formatted the same way. This made it easier to design an algorithm to extract the cell’s content from the PDF table.
Once the PDF data extracted, the software create an Excel file. XLSX files tend to be more open that its old counterpart binary format XLS, so it’s rather easy to work with Excel files nowadays.
The new Excel files are just zips that contain a bunch files and folders of relationships and objects. A nice introduction about the internal structure of the OpenXML (Microsoft Office) files can be found here.
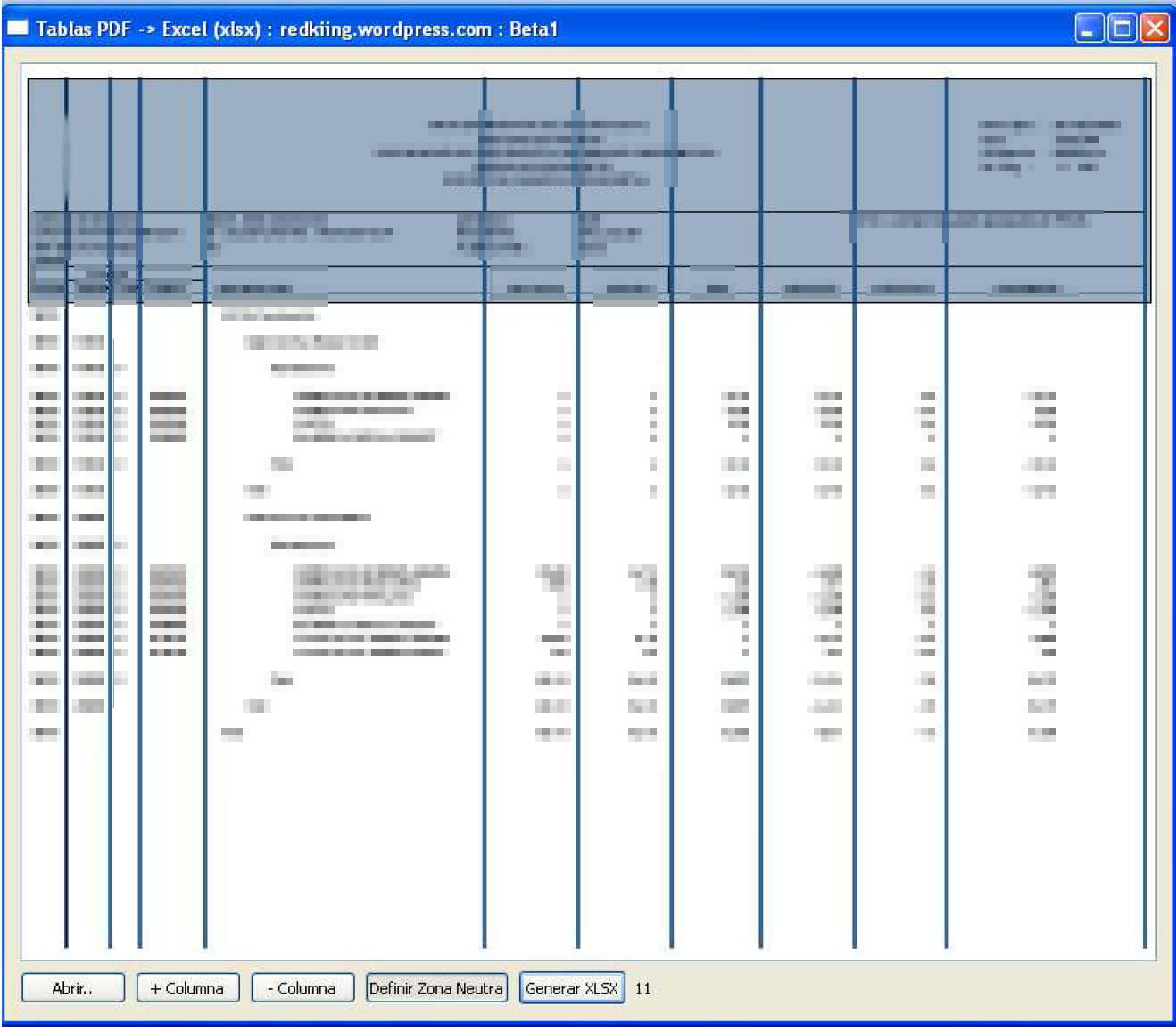
A Qt Interface shows one page of the PDF file. Once you’ve chosen which file you want to work with, you can choose what sections of the document you don’t want to extract (blue area) and where the columns should be placed (blue lines).
The software is very fast. It can parse a 1000 pages PDF in less than 2 minutes. It removes empty lines, so even if the original file has a lot of blanks, you’ll end with the data you want to extract. And it’s really easy to use, you just have to click the “generate XLSX file” button and you’re done.
A very big limitation of this utility is that the PDF parser will not work with every PDF. However, the software can easily be customized to work for specific purposes.