
I have always been rather excited about giving human-like abilities to machines. When I first read Gaty’s paper explaining how computers could create art by applying artistic styles to pictures, I was amazed to put it simply. I told to myself then that I would build a website for everyone to try this out. A couple of years later, I built such a system. This blog post outlines the architectural choices that power picmatix.com since early 2017.
You may or may not find all parts interesting, so feel free to jump around.
Why?
Bringing projects to life is always exciting. Picmatix.com being at the intersection of Machine Learning and Software Engineering was the perfect testbed to take state-of-the-art ML models to a production environment and as a playground to test new software architectures that would otherwise be too risky to try in an Enterprise setting.
How it works
A user navigates to picmatix.com, uploads a picture and choses one of the hand-picked styles. The website then does the grunt work of rendering the artwork and sending an email to the user when it is done ‘painting’.

1. Upload a picture
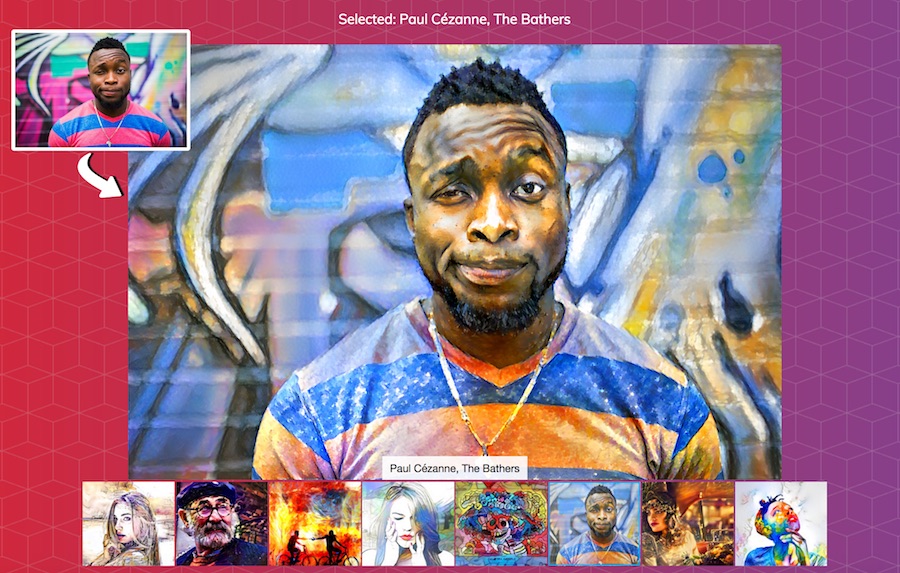
2. Choose a Style
After a day or a week (if I am not around), the user gets an email with a link to preview the artwork. For the curious, I am using this carefully crafted litmus template.
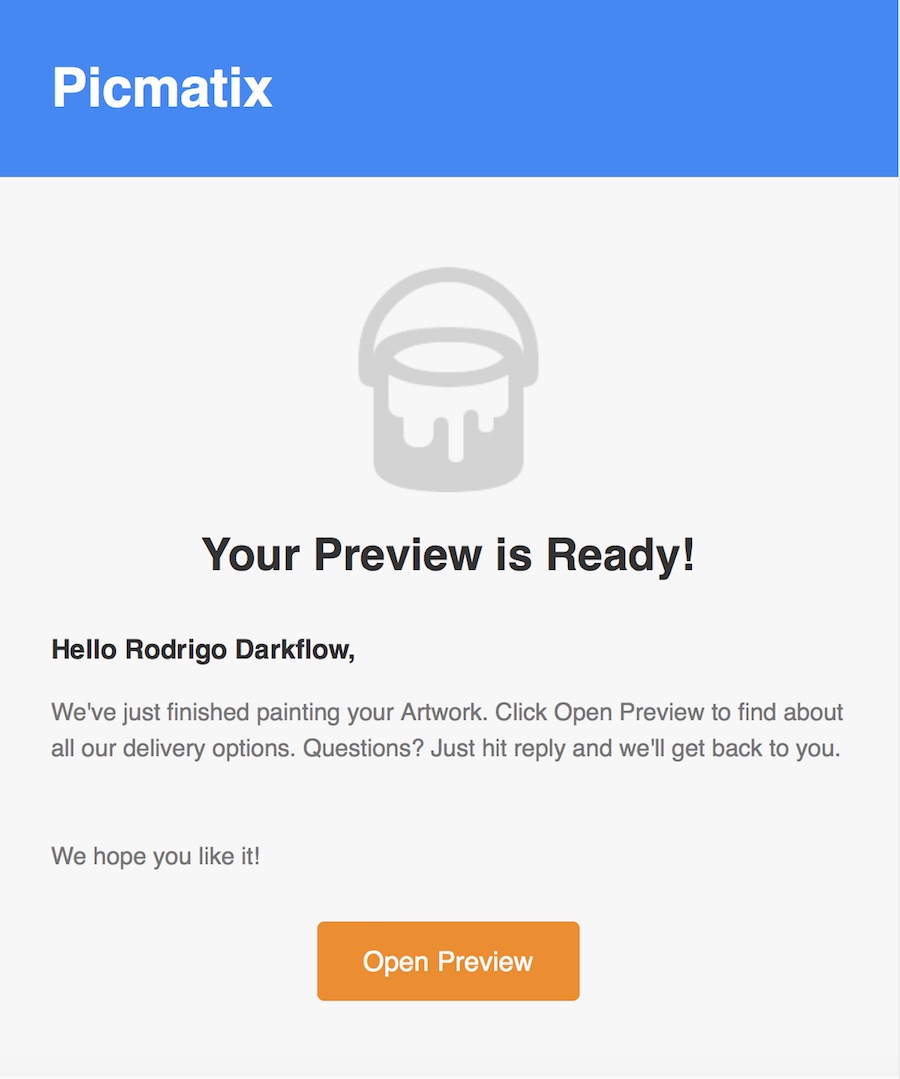
Your Preview is ready
Clicking ‘Open Preview’ takes the user to a page where they can buy the HD version if they like it. They can even set their own price!
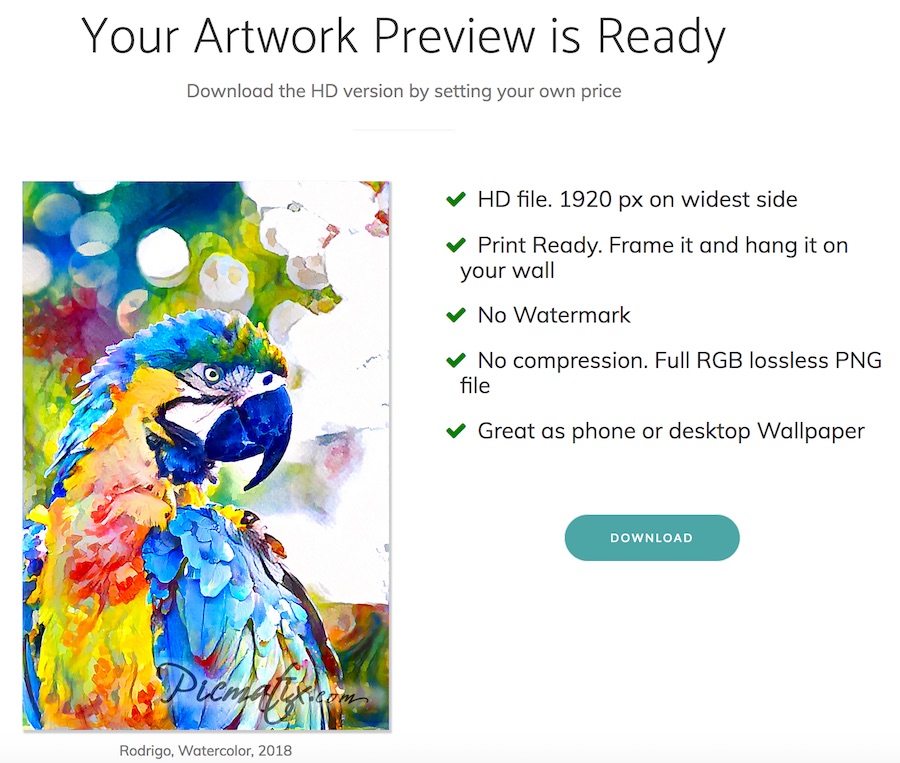
Preview page
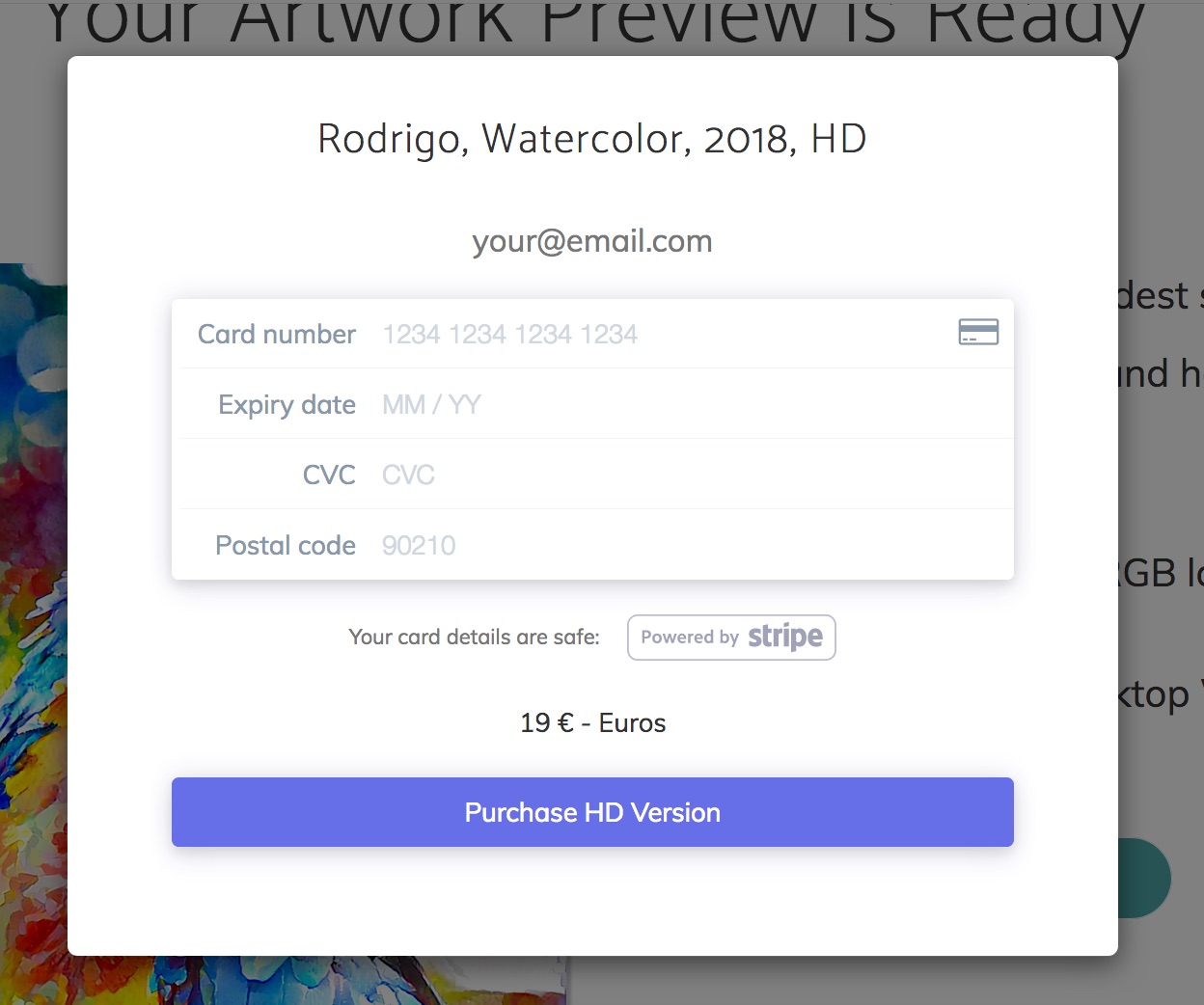
Purchase page

Artwork rendered by picmatix.com
Behind the scenes
One of my non-functional goals early on was to build this system as cost-effectively as possible. This was possible by wisely choosing the architecture to use few to no servers, or in trendy words: serverless.
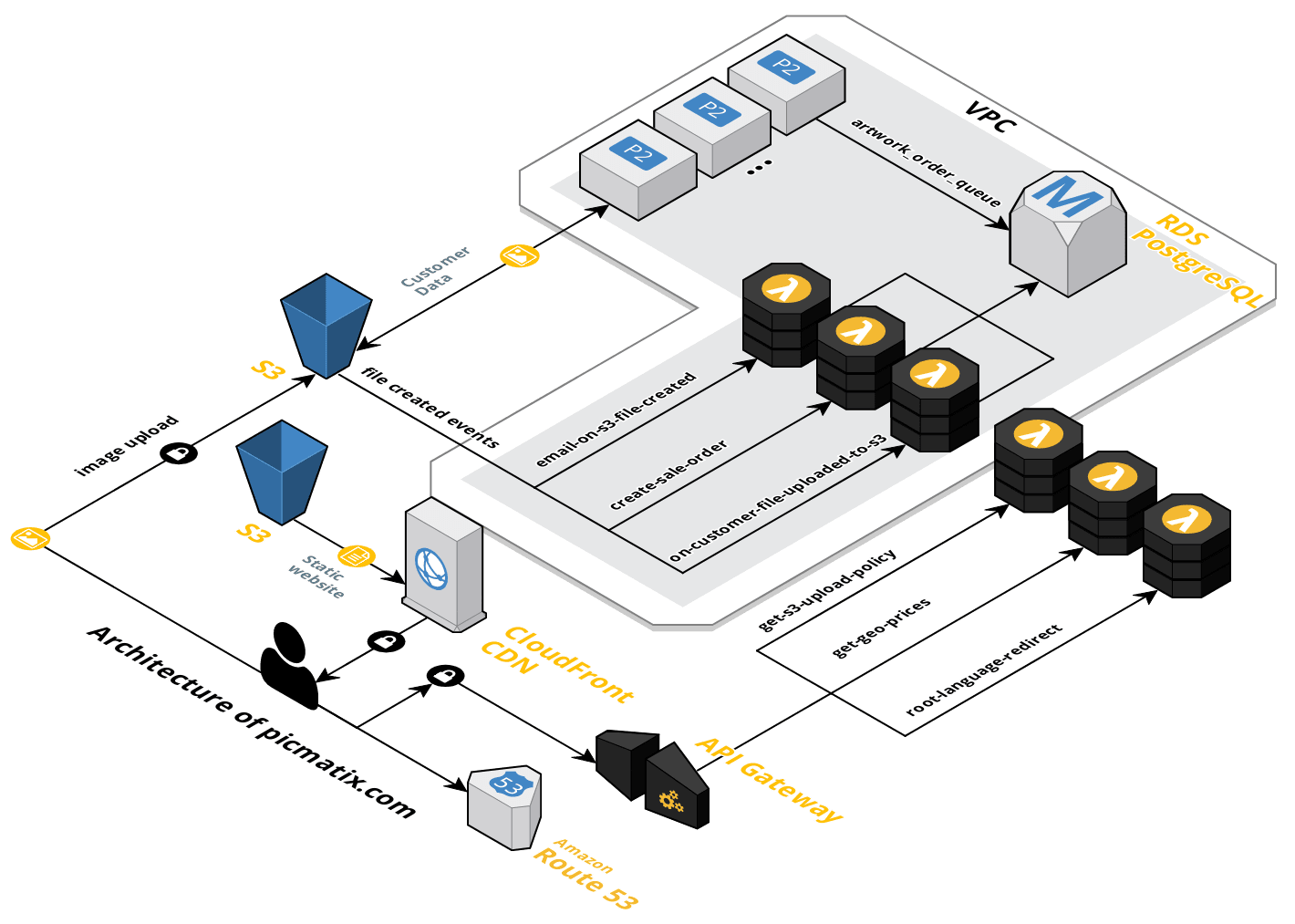
Serverless architecture of picmatix.com
Website and Hosting
The website itself is built with hugo. I am a big fan of static websites and an avid avoider of WordPress. Specifically, I am strongly against using a database to render websites where simple static files suffice.
The website itself is hosted on AWS S3, delivered through Amazon’s CloudFront CDN and uses Amazon’s Certificate Manager infrastructure to deliver all content through https. In other words, I (almost) never need to worry about the website going down nor about maintaining it. Funny enough, the day I launched my 1st marketing campaign on Facebook, the website went offline for several hours due to an S3 outage. Go figure.
I used Gandi.net to purchase the domain and AWS Route 53 to handle all DNS queries.
Front-end stack
I love experimenting with new technologies and languages. At NewsWhip I experienced first hand, the productivity boost we got from moving off from jQuery to AngularJS. Nevertheless, the functionality needed in this app was essentially just a User Form, on steroids if you wish, but still a User Form: enter some details, the data gets uploaded to the cloud and a screen appears to say everything was ok.
jQuery was the fastest way I knew then to bring this app from idea to reality. If I were doing it again, I would most certainly use VueJS instead, as it delivers everything you may need to build modern web apps without forcing you to set up complex tooling when it isn’t needed.
Staging infrastructure
It is sometimes useful to make changes without affecting end users, so I set up a staging environment for this. Thanks to the serverless nature of the architecture, this was very easy to do. There is a staging replica for every feature, database, and API endpoint.
Deploying changes
At NewsWhip I really loved how easy it was to deploy changes with Heroku style deployments: git push serverName master. This involved then, setting up server-side hooks to compile and deploy the apps. This was, however, far too complex for this project. I opted for a simple bash script that compiles the website with hugo and deploys the result to AWS S3. The script looks very similar to this:
hugo
aws s3 sync ./public s3://website-bucket/ --delete
Payments
This was a no-brainer. I used Stripe which is by far the easiest way to accept credit card payments. Not knowing how much to charge users, I opted for letting them set their own price. ‘Innovate the product or the pricing but not both’. I did both.
Backend and API Endpoints
get-s3-upload-policy
In the same vein of reducing the infrastructure overhead (including money and time spent). I adopted the new AWS serverless stack: AWS Lambda functions. All API endpoints and most of the (event-driven) backend is written as Lambda functions. It turned out to be extremely easy to create and deploy Lambda functions. Mostly thanks to the extensive use of apex.run, a tool that helps developers build, deploy an manage AWS Lambda functions.
At the beginning of the project, I tried using serverless.com to deploy changes, but there was way too much overhead when deploying simple Lambda functions. On a slow internet connection, a few lines of code would take more than a minute to deploy due to all the extra work this framework does (setting up a CloudFormation template, sending files to S3, creating buckets, updating this and that, etc). Apex.run being much simpler and AWS focused was a much better fit. Things might be different now.
Language redirect
root-language-redirect
The root domain, picmatix.com, is not a static HTML site. Instead, it is an API endpoint that redirects users to the most likely language they speak (only English and Spanish are supported at this time). The whole app, including emails and web pages, are fully translated. This is possible thanks to hugo’s native multilanguage support. The redirect code is very simple. In fact, it fits in just a few lines of code. It maps the content of the Accept-Language browser header to any of the supported languages and returns a new URL in a 303 redirect:
'use strict';
const locale = require("locale");
const supported = new locale.Locales(["en", "es"], "en");
const bestLanguageCode = function(acceptLanguageHeader) {
return (new locale.Locales(acceptLanguageHeader)).best(supported).toString();
}
module.exports.rootLanguageRedirect = (event, context, callback) => {
const headers = event.headers || {};
const acceptLanguage = headers['Accept-Language'];
const response = {
statusCode: 303,
body: JSON.stringify({
}),
headers: {
'Location': '/' + bestLanguageCode(acceptLanguage) + '/'
}
};
callback(null, response);
};
AWS Lambda functions cannot be accessed directly from the Internet, therefore, an AWS API Gateway is required to proxy browser requests to Lambda endpoints.
Securely uploading images to S3 from the browser
get-s3-upload-policy
As there are no servers involved. I had to figure out a way to securely upload images to S3. Fortunately, AWS provides this functionality through the use of custom signed policies. Essentially, your browser sends the images directly to S3 along with a signed policy that allows this particular query to succeed so others can’t upload content without your permission. To prevent automated bots from sending content to S3 I implemented Google’s ReCaptcha on each form upload.
Populating the database
on-customer-file-uploaded-to-s3
When an image is uploaded to S3, AWS generates an event which I wired to an AWS Lambda function. The S3 image itself contains all user input data as metadata, including the style of their choosing and the user contact details. While this is a very useful feature, S3 makes a terrible database when used in this form. This Lambda function takes the file metadata and populates an RDS Database running PostgreSQL. The artwork_order_queue table looks like this:
CREATE TABLE IF NOT EXISTS artwork_order_queue (
artwork_order_queue_id SERIAL PRIMARY KEY,
artwork_order_id INTEGER UNIQUE NOT NULL REFERENCES artwork_order(artwork_order_id),
is_done BOOLEAN NOT NULL DEFAULT 'f',
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);
One nice property of hosting everything on AWS (Lambda functions, the RDS database, and style transfer servers) is that they all can run within an AWS VPC (Virtual Private Cloud). Making all internal traffic essentially private to any 3rd parties or eavesdroppers.
On the downside, AWS is expensive. A few months in, I migrated the database from RDS to a small, less expensive instance hosted in vultr.com. To keep the database connections secure I set up Postgres to use SSL certificates.
Style Transfer Backend
Every once in a while I manually launch an AWS EC2 spot p2.xlarge instance which runs a Java app. This app connects to the SQL database and processes any artwork requests that haven’t yet been processed. The app has been specifically written with multi-instance support in mind. That is, if all of a sudden I have a hundred or thousand artwork requests, I could launch a few p2.xlarge servers at once and they will all process different parts of the artwork_order_queue in parallel. To make this all work I am using the SKIP LOCKED feature in PostgreSQL as the building block of a concurrent work queue:
BEGIN;
UPDATE artwork_order_queue
SET is_done = TRUE
WHERE artwork_order_id = (
SELECT artwork_order_id
FROM artwork_order_queue
WHERE NOT is_done
ORDER BY artwork_order_queue_id ASC
FOR UPDATE SKIP LOCKED
LIMIT 1
)
RETURNING artwork_order_id;
--- CALL_CREATE_ARTWORK_FUNCTION()
COMMIT;
The CALL_CREATE_ARTWORK_FUNCTION is implemented through a series of bash scripts that eventually use the style transfer Lua code written by @jcjohnson. Unlike the original paper, the output image is generated through multiple render passes using a VGG-19 neural network trained on ImageNet. The script creates a low resolution highly stylized image which is then used as input to create the higher resolution image. This generally returns much better looking results when compared to a single high resolution pass. Each style uses a different set of weights, content, and style layers:
th neural_style.lua \
-content_image $CONTENT_IMAGE \
-style_image $STYLE_IMAGE \
-init image \
-style_scale $STYLE_SCALE \
-print_iter 50 \
-style_weight $STYLE_WEIGHT -content_layers "$CONTENT_LAYERS" -style_layers "$STYLE_LAYERS_STEP_1" \
-image_size 350 \
-num_iterations 400 \
-save_iter 100 \
-output_image "$OUT_FILE" \
-tv_weight 0.0001 \
-backend cudnn -cudnn_autotune
th neural_style.lua \
-content_image $CONTENT_IMAGE \
-style_image $STYLE_IMAGE \
-init image -init_image "${OUT_FOLDER}/out3.png" \
-style_scale $STYLE_SCALE \
-print_iter 50 \
-style_weight $STYLE_WEIGHT $LAYERS_STEP_2_3 \
-image_size 960 \
-num_iterations 200 \
-save_iter 50 \
-output_image "$OUT_FILE" \
-tv_weight 0.001 \
-backend cudnn -cudnn_autotune
The output colors are generally a bit pale, so I do some post-processing with Image Magick to brighten the colors and smooth out some edges. Again, each style has its own set of parameters. I also add a watermark logo to the image to encourage sales:
convert "${OUT_FOLDER}/out.png" $CONVERT_ARGS "${OUT_FOLDER}/out.normalized.png"
As the image is not nearly large enough for printing. I pass it through Waifu2x to double its size and smooth out some imperfections:
th waifu2x.lua -m noise_scale -noise_level 2 -i "${OUT_FOLDER}/out.normalized.png" -o "$OUT_FILE" -force_cudnn 1
Finally, the resulting image is uploaded to S3 and the next pending artwork request is processed:
aws s3 sync ./output-folder s3://s3-bucket/output-folder
It usually takes around 7 minutes for a single HD image to be generated. I toyed with the idea of using the much faster (in the order of one second per image) fast style transfer algorithm for which I wrote a PyTorch open source tool. Sadly, the results are not nearly as good:

Artwork generated with Fast Style Transfer, Style Darkan

Artwork generated with (slow) Style Transfer, Style Darkan
email-on-s3-file-created
Once a preview image has been generated. An S3 file-created-event is fired, which then executes a Lambda function that sends an email to the user with a link to preview the image. This link is uniquely generated and cannot be guessed. This guarantees the user’s privacy.
get-geo-prices
To improve the user experience, the pricing page is shown in the user’s preferred currency. This is done by calling a Lambda function which maps the user’s IP to a country which then maps to a currency and a price suggestion.
create-sale-order
Once the user pays for an artwork using Stripe’s Elements widgets, Stripe calls a public Lambda endpoint (webhook) with the purchase details (artwork sold, user, price, etc). No card details are ever transferred to AWS. This function updates the database and sends an email to the user with a download link to their HD artwork.
There are a few other Lambda functions for tracking and understanding user behaviour and for refreshing S3 tokens, but other than that this is pretty much it!
Serverless deployments
apex.run takes care of everything. I simply do:
# Deploys to staging environment
apex deploy
# or
# Deploys to production environment
apex deploy --env prod
Style Transfer Backend deployments
I set up a p2.xlarge instance and created an AMI out of it. This AMI runs an init script that syncs an S3 folder locally and executes another script which eventually downloads the Java app and dependencies that run the style transfer. This guarantees that the AMI is always up to date with the code, models, and styles regardless of when it was created. Deploying a new version of the style transfer backend is done with a script that essentially boils down to this:
#!/bin/bash
# Usage: ./scripts/deploy.sh
set -e
# Build backend
cd ./backend/functions/style-transfer-worker
gradle build
cd -
# Transfer to model, styles and app to AWS
aws s3 sync ./backend/ s3://s3-bucket-backend/ --sse AES256
In practice, the script deploys the backend to all AWS regions where p2.xlarge instances are supported. This allows me to choose the least expensive spot instance Availability Zone across all AWS regions.
Failure Modes
There are several ways the app can fail or go down. From likely to unlikely:
- The database is unreachable:
- All Lambda functions that use the database remain unavailable. In particular:
- Stripe would retry calling the payments Lambda webhook and no HD links would be emailed to clients until the database is back up
- S3/Lambda would retry updating the database up to 3 times, after which the database would become out of sync with respect to S3
- No artworks can be created
- All Lambda functions that use the database remain unavailable. In particular:
- S3 goes offline: the website becomes unavailable and no users can’t use the site
- Human errors:
- data gets deleted by accident: apologize and recover what you can
- AWS misconfiguration
- Stripe goes offline: no purchases can be done
- Cyber attacks
- AWS Lambda goes offline: uploading images and payments is not possible
- AWS S3 misses sending some events: affected customer images won’t be processed until the database gets resynced
One of the most critical issues above is the possibility of the database going out of sync with respect to the user data in S3. To work around this, I wrote a Java app that checks all files in S3 and adds any missing artwork requests to the database. I have yet to use this tool in production.
Results
Building picmatix.com has been a thrilling project. Putting Machine Learning models live in production is not an easy feat yet. And while the use case of picmatix.com is ultimately quite limited, It was a great way to test new ideas.
One thing to note is that Machine Learning model are not perfect. The models and styles don’t always work and in many cases, they fail miserably. I noticed early on that faces didn’t work that well when they were not large enough. Hence the marketing focus on pets and animals. Short list of things that don’t work well in picmatix.com:
- Style Transfer:
- Small faces, teeth, eyes
- Small objects
- Landscapes
- Flowers
Furthermore, when timing wasn’t particuarly the best when I launched the site:
- There are plenty of free competitors out there. Convincing users to use this instead, is a hard sell
The whole style transfer process is slow. Moving on to a real-time transfer style might have brought better chances for this product to be widely used. The slow delays of 1 day or more have been a significant impediment to the business success of this project.
On a more technical aspect:
- Lambda functions are great for small deploy-and-forget projects, but they are much harder to monitor than standard monolith projects where you can just tail a log file and you are done. In AWS you are most likely to use CloudWatch which IMO it is not nearly as good as using plain old flat files
- Java Lambda functions can be slow the first time they are used (cold-start). As such, I would not recommend them to power the backend of (rarely used) public API endpoints as their latency can be really high (in the order of seconds)
- Furthermore, running Lambda functions inside a VPC adds additional latency as an ENI (Elastic Network Interface) has to be attached to the Lambda function before its execution (e.g. connection to RDS within a VPC)
- Having many small functions that do one thing and only one thing well sounds great in theory. But in practice, it results in a high cognitive overhead when trying to build a mental model of what does what and where. I have personally had much more success in navigating large single project/monolithic codebases with the help of powerful IDEs (e.g. IntelliJ)
- Reusing someone else’s code is a huge time saver. Long live open source!
Thanks for reading
I welcome any feedback and would love to hear what you would have done differently. There are more renders available on Picmatix Facebook page.
I am aware of the fact that I glossed over many details, if there is enough interest I may look into open sourcing the project. Here, have a cat.

Internet Cat
