
Introduction
There is still too much information we do not need on the B&W image we got on the last step. That’s why we need to extract the features we do need. One way of accomplishing this is by performing a connected component analysis in binary images, aka blob labelling. However as you’ll will see, this method is not completely adapted to our needs, so a new approach is proposed: Blob Edge Detection.
First approach : blob detection
cvBlob is a nice library that has many interesting functionalities such as: binary labelling and features extraction, blob tracking and contour detection. It is powered by openCV under the hood.
In the beginning of the project I wondered whether this library would be useful for what we were trying to accomplish. I ran some tests and even though the binary labelling approach proposed by cvBlob was good and very fast, it wasn’t good enough. By using their approach we could have only found the position of single pawns. For instance, the following image uses cvBlob and shows some pawns being correctly recognised, each pawn is labelled with different colours.
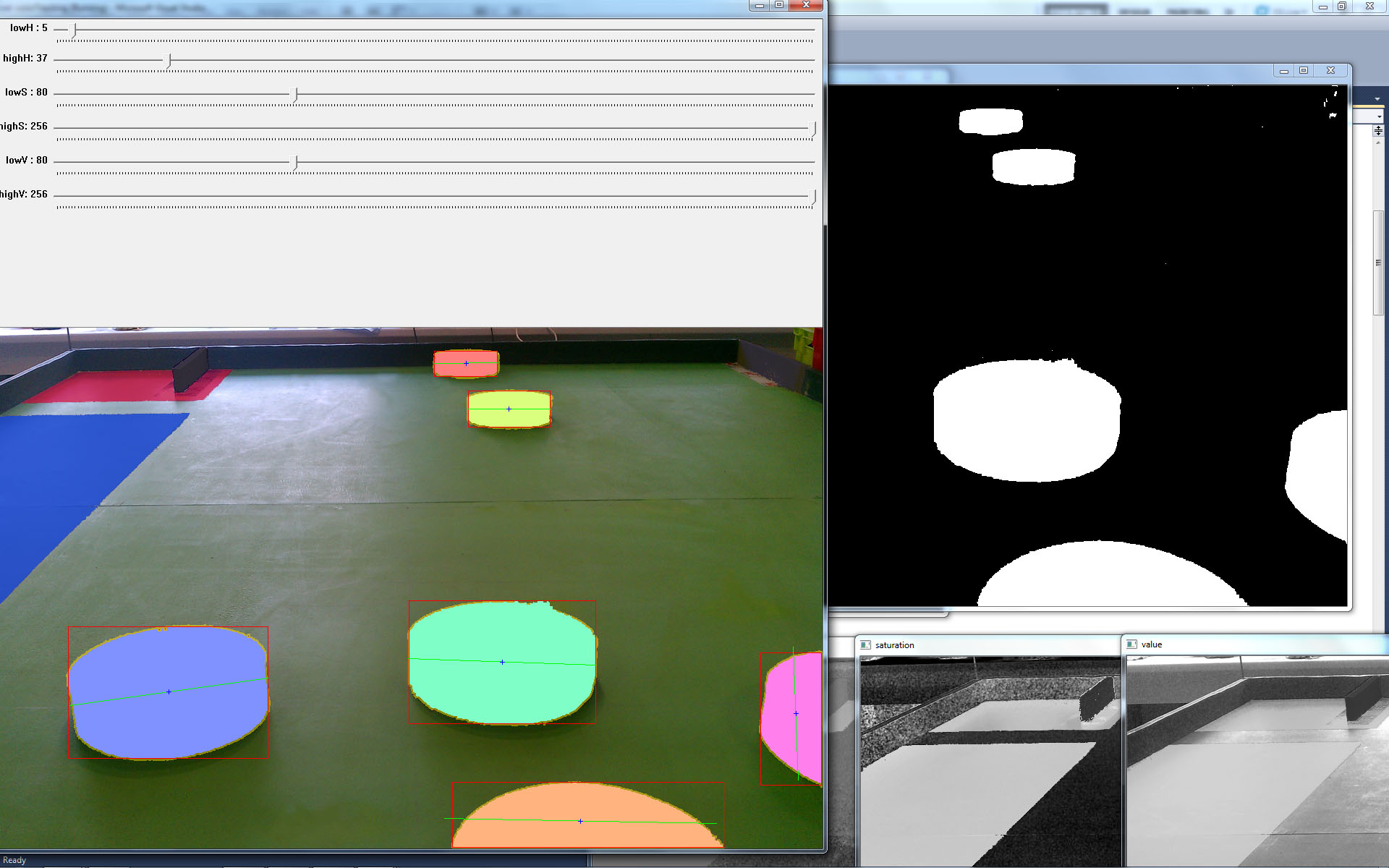
Problems appeared in more complex situations where several pawns were labelled as a single pawn or where a pawn was labelled twice. The following image shows a group of 3 and 2 different pawns being labelled with the same colour pink and green respectively. This behaviour is caused because those pawns are connected and form a single blob on the binary image (not shown) and thus are labelled with the same colour.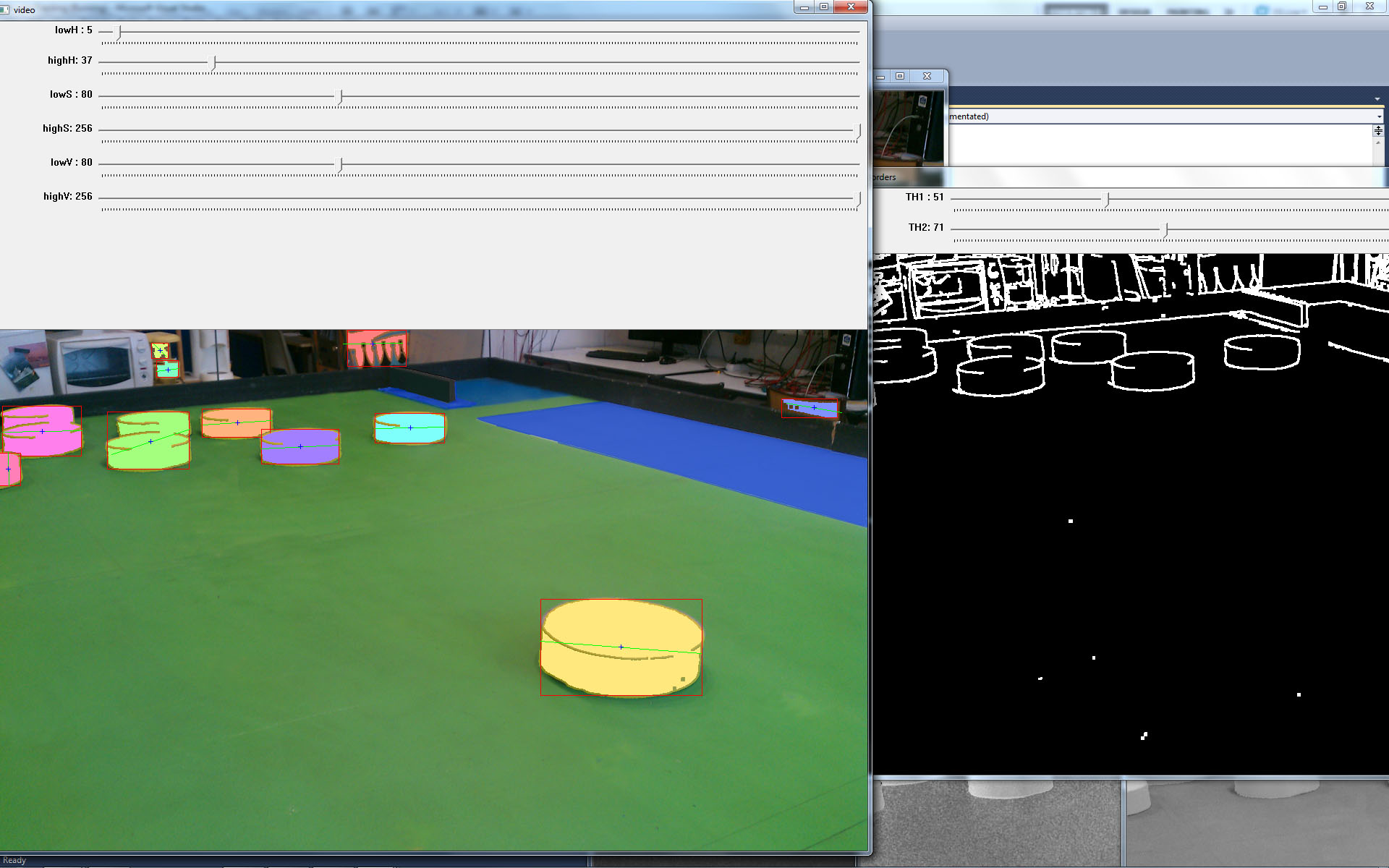
The other problem with this method was that some pawns were detected twice. The following image shows a pawn at the right bottom corner being labelled twice (pink and purple) due to the fact that the pawn on the binary image is composed of 2 separate blobs.
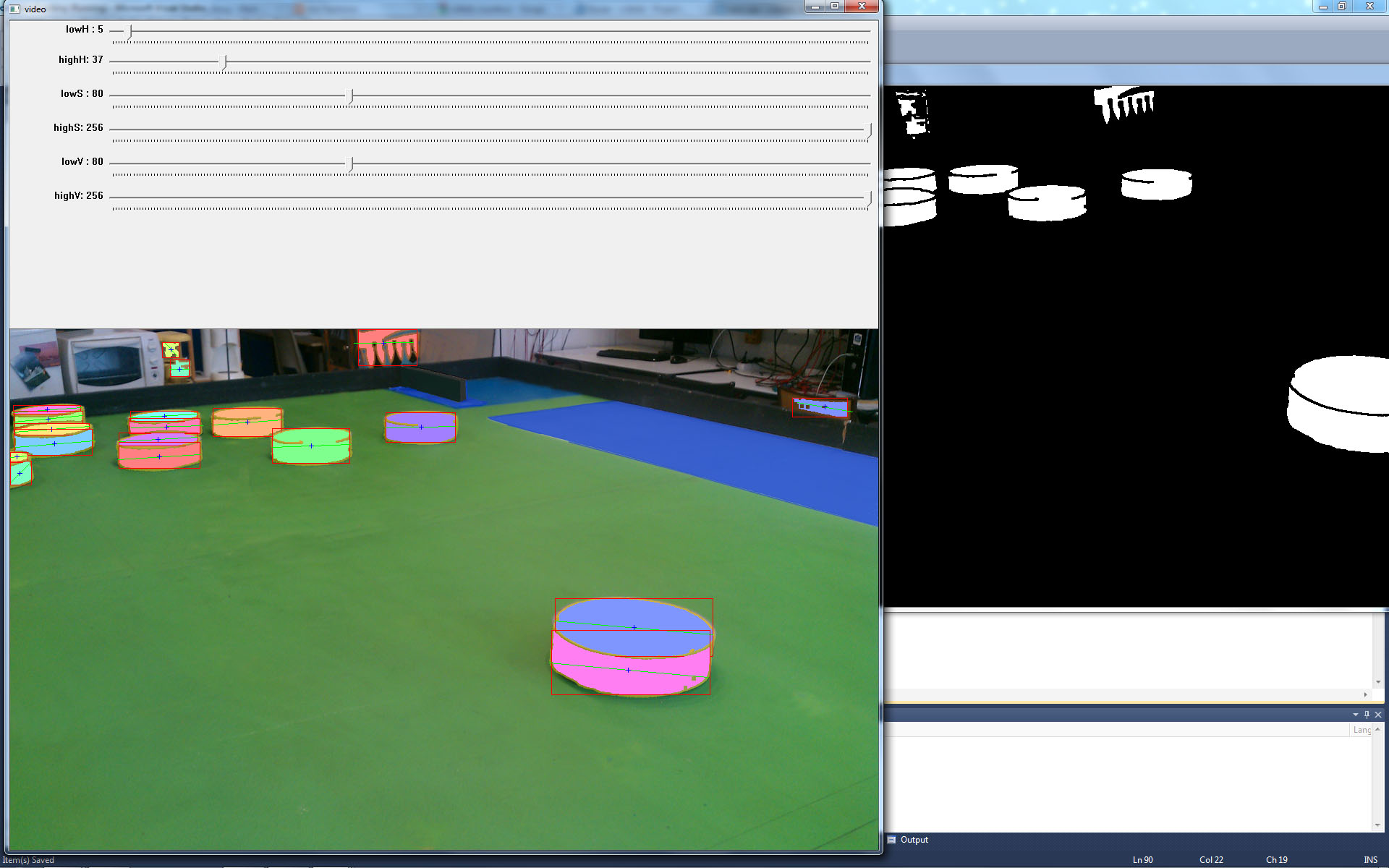 In order to achieve better object detection results, a more robust algorithm was implemented.
In order to achieve better object detection results, a more robust algorithm was implemented.
Algorithm
The main idea behind the algorithm is to separate tower of pawns or single pawns from other pawns. One way of doing it is by searching and labelling blobs' bottom edges.


-
- Find the blobs' bottom edges
Take the B&W image
for every column of the image do
for every row
if the pixel is black and the N previous pixels above it are white
and if the black gap after the current pixel is big enough then
mark the pixel as being a bottom edge of a pawn
end if
end for every row
end for every column
-
- At this point we have a set of pixels P that belong to the bottom of pawns. They are however scattered throughout the rows. The next step is to regroup those pixels by pawns as much as possible. This means to check whether a pixel p from P belongs to the same bottom edge of a given pawn.
Take the set of pixels P that belong to the bottom of pawns
P(1) being the set of pixels P whose column is 1
Create a new list of bottom edges for every pixel p belonging to P(1) and add every p as a first element to them
for every column c of the image, starting with the 2nd one
for every set of pixels p in P(c)
if p is near any other pixel w in P(c - 1) then
add p to the list where w is located
else
create a new list of bottom edges
add p to the list
end if
end for set of pixels
end for every column
-
- Now we have a list of bottom lines L, each containing a list of pixels that belong to the bottom of a pawn or a tower of pawns. Unfortunately some contiguous lines do not belong to the same pawn. The following image shows an example of such kind of errors.

This has to be fixed otherwise we’ll be unable to find the right position of the pawn. The following algorithm fixes this problem.
for every bottom line l of L
if the line l has a spike, split l at the spike
end for
Results
The algorithm’s output for the B&W image shown at (1) is shown in the following rendering. Every bottom line l from (L) has been coloured differently to better show the result of the algorithm. A similar approach has been applied to detect the upper edges of the pawns.
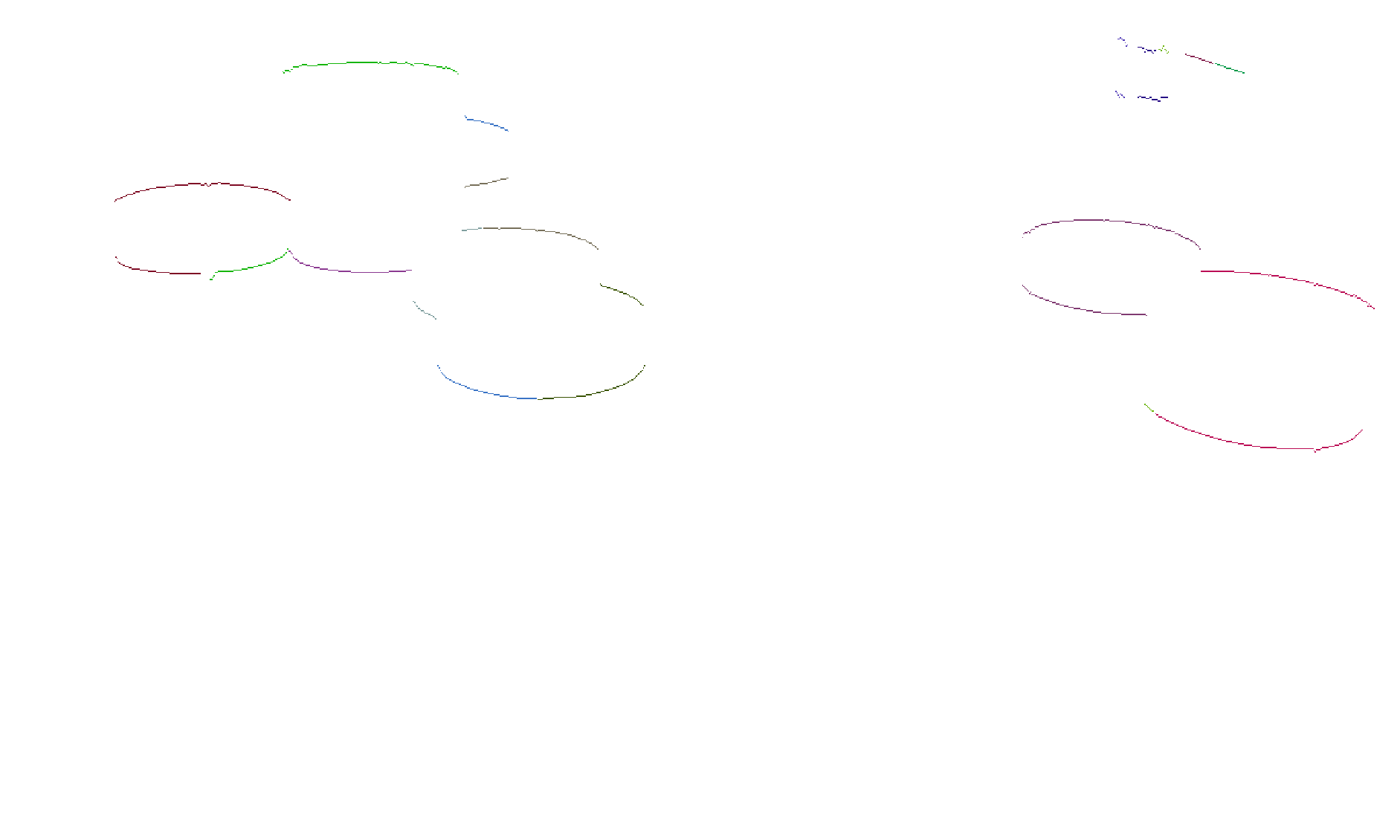
As you may see, any one line belongs to the bottom of one and only one pawn. The reciprocal is not true: two or more lines might belong to the same pawn. This is not a problem as you’ll see later on.
Discussion
Advantages
The advantages of the BLED algorithm are :
- Tower invariant: tower of pawns are not special cases, they are treated and located as if they were single pawns.
- Faster than a simple labelling algorithm: the algorithm is faster because only blobs' bottom edges are connected and labelled. Whereas the other algorithm connects all pixels of a blob.
- Noise resistant
Optimizations
The algorithm in (1) is slow because its searches every pixel of every row of the image. One way of optimizing it is by searching every T rows for white to black changes where T is the minimum gap size between two blobs to be considered different blobs. Once a colour variation is found, search down the image to precisely detect where the white to black change happens. This optimisation is somewhat similar to the idea behind pyramids but without the aliasing nor the copy of image data overhead.
Disadvantages
- The current algorithm cannot find the height of towers.
- Pawns that are exactly behind other pawns are simply ignored and not found.
- If an object, such as a robotic arm, is placed between the camera and the middle of a tower of pawns, the algorithm might consider the tower as being two different pawns at different positions.
Other approaches
In order to detect the pawns' edges, we could have simply used the more common Canny Edge Detector. However, we might have needed to use morphological operations on the image before applying the edge detector, to reduce the heavy noise inherent to the previous colour thresholding step. Moreover, this approach would have found all edges: bottom, upper, left and right of a pawn. A second step would have been necessary so as to extract the bottom edges only, which may be far too complex to do. In summary, by using the Canny Edge Detector we would have added too much of an overhead.
What’s next
We now know where the pawns are on-screen, but how does that help us to know where they are on the game field ? That’s the whole point of the next post : Transformation.