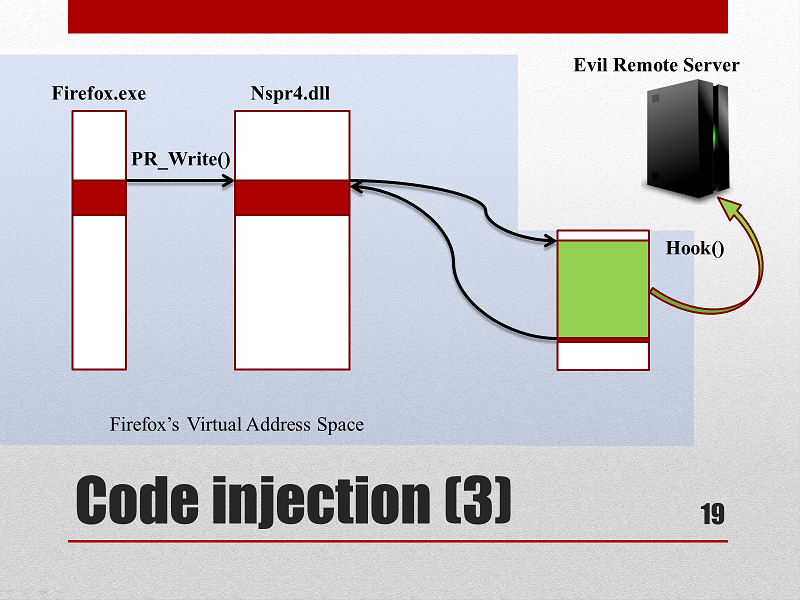
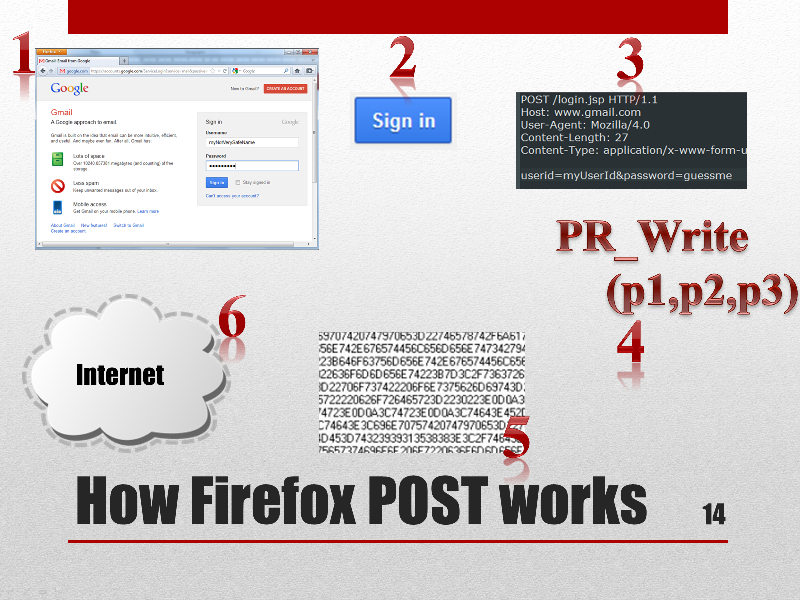
FormGrabber Almost every sensitive information, such as passwords, login credentials, bank account numbers, credit card numbers, etc, is sent from your web browser when you fill an online “form” to a secure remote sever trough the web standard HTTPS POST.
A form grabber is a malicious code that intercepts POST data coming from web “forms” before the encryption takes place, thus avoiding the added security of the https protocol.
Our FormGrabber We have successfully implemented a form grabber that grabs all POST data and sends it to a remote server for a later use.
Continue reading
Introduction
The following series of posts represent the completion of a university research project and a compilation of what has been said at INSA de Lyon the 26 of April 2012. You can find the slides here. I highly encourage you to read these posts while browsing through the presentation.
I am not responsible whatsoever of the use or misuse of the information hereafter. Be wise.

Continue reading
You’ll find in this post a summary about all the cool stuff I witnessed through out 2011.
Last year came with a heavy agenda. Lots of public events took place during the year. I participated with my ClubElek team-mates at 3 different exhibitions and 4 different contests.

Continue reading
Introduction
Let’s do a summary of what we have done so far:
- COT: colour thresholding. We separated yellow objects from the rest.
- BLED: blob edge detection. We retrieved the bottom edges of blobs (pawns).
- T: transformation. We transformed the image’s pixels into game field points (aka. pixels to meters).
And the last step CID: Circles Detection.
As you may have already noticed, pawns and tower of pawns are in fact circles when viewed from above. Therefore, the bottom edges we found with BLED are also circles' segments when transformed into game field coordinates (step T). This is the property we’re exploiting below.

Continue reading
Introduction
With the last step we know where the bottom edges of the pawn are located on the image, we just need to find a way to transform the coordinates of those pixels into game field coordinates.
Given a point $p' $ from the Image plane, we’d like to transform it into $ p$ from the Game field plane. We can write:
$ p = H \cdot p'$
We observe that straight lines are kept straight, thus H is called the homography matrix which can be computed if at least 4 different matching points are given for both planes. $ (p1 \leftrightarrow p1', p2 \leftrightarrow p2', p3 \leftrightarrow p3', p4 \leftrightarrow p4')$

Continue reading
Introduction
There is still too much information we do not need on the B&W image we got on the last step. That’s why we need to extract the features we do need. One way of accomplishing this is by performing a connected component analysis in binary images, aka blob labelling. However as you’ll will see, this method is not completely adapted to our needs, so a new approach is proposed: Blob Edge Detection.
Continue reading
Introduction
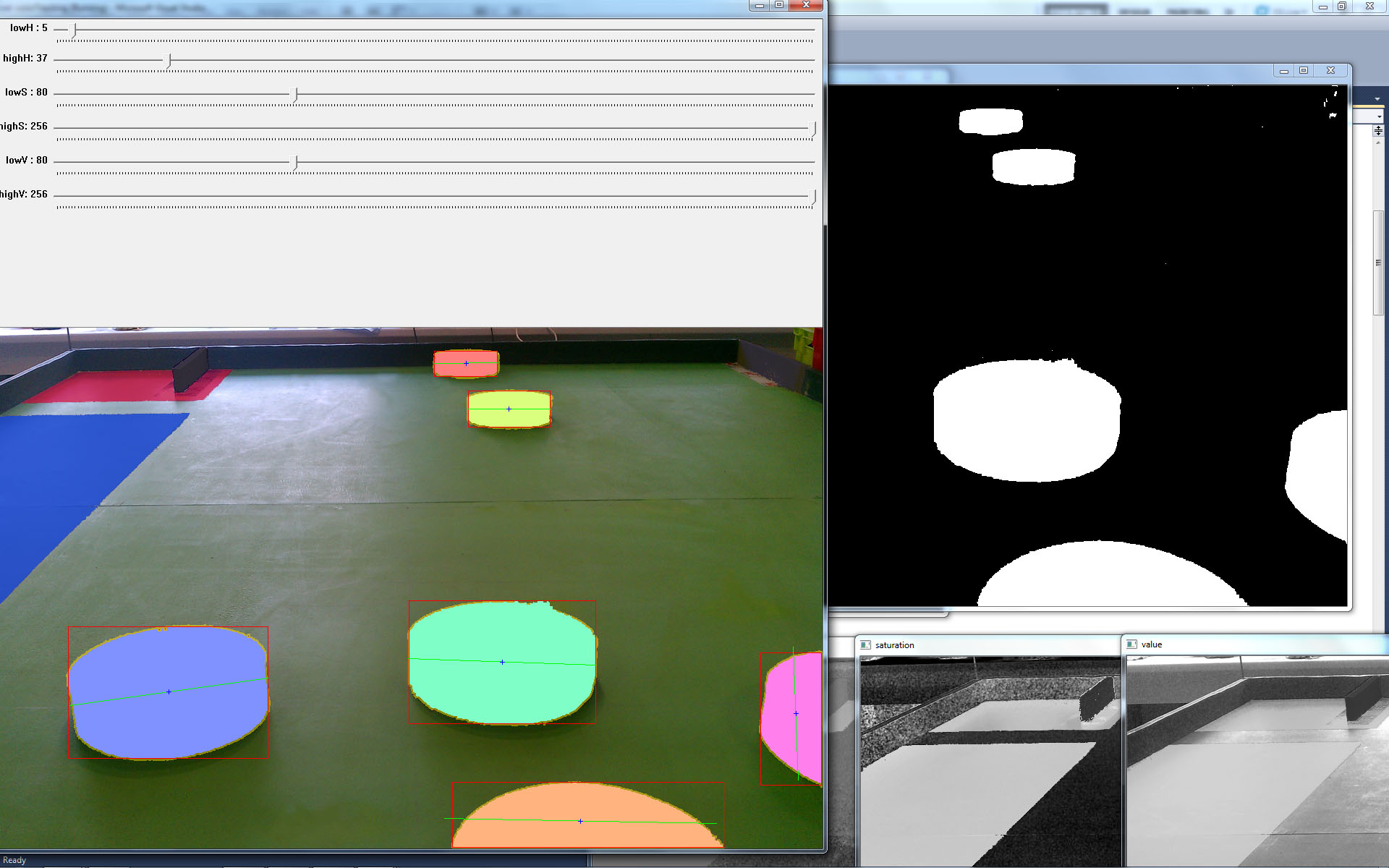
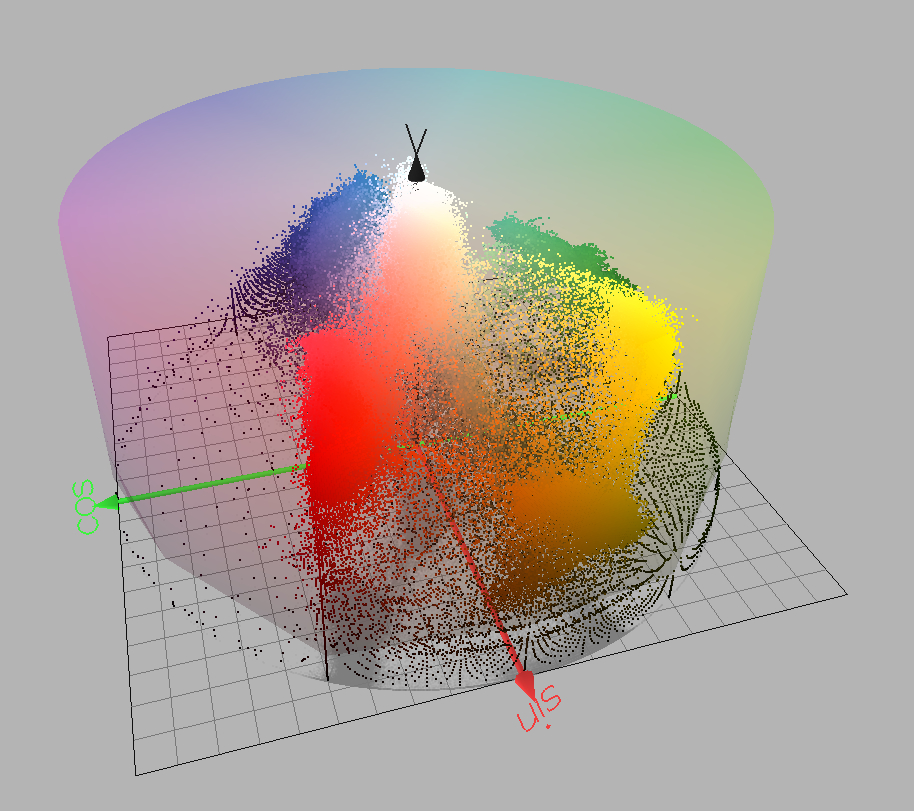
Images are usually too complex to be treated by computers as is. In most cases, they have to be enhanced and simplified before any algorithm can be applied on them. Fortunately for us, the rules of the contest specify that yellow is the colour of pawns and figures we are looking to detect.
Generally speaking, the purpose of Colour Segmentation is to extract information from an image by grouping similar colours. In our algorithm, we implemented colour segmentation by thresholding yellow colours, that is to say, the computer builds a black and white image from the original image where white colour represents yellow colour and black is everything else. This is called colour thresholding.
The problem is, as you may have already guessed, the notion of “yellow” colour. For humans, it is relatively easy to tell whether a colour belongs to a group of colours, but for computers this is a whole different story.
Continue reading
Introduction A fancy acronym that stands for the process of COlour Thresholding, Blob Edge Detection, Transformation and CIrcle Detection used for locating 3D objects on a plane. The next series of posts will explain the software algorithms used by ClubElek on 2011 to achieve computer vision. The problems we faced, the solutions we implemented and most importantly what we have learned by doing this project.
These posts are targeted to a wide audience with some background in maths and preferably some background in computer vision.

Continue reading
As you might have already noticed, the internal’s opencv camera interface is far from complete. You can capture video from your camera without a hassle but you’re very limited to what you can do.
For instance, let’s say you have a webcam that can run at HD resolution ( 1280 x 720 px ), you can use the opencv’s class cv::VideoCapture to get the frames but you’re going to have a hard time on getting the full resolution out of your device.
To sort out this problem, one could use specialized libraries. The disadvantage : they’re not usually multi platform so you’ll find yourself writing classes for every platform where you’re camera device operates.
Theo developed a very useful video capture library for windows called videoInput.

Continue reading